Can we improve transfer accuracy by changing how we sample few-shot classification episodes? Yes, here’s how.
Summary
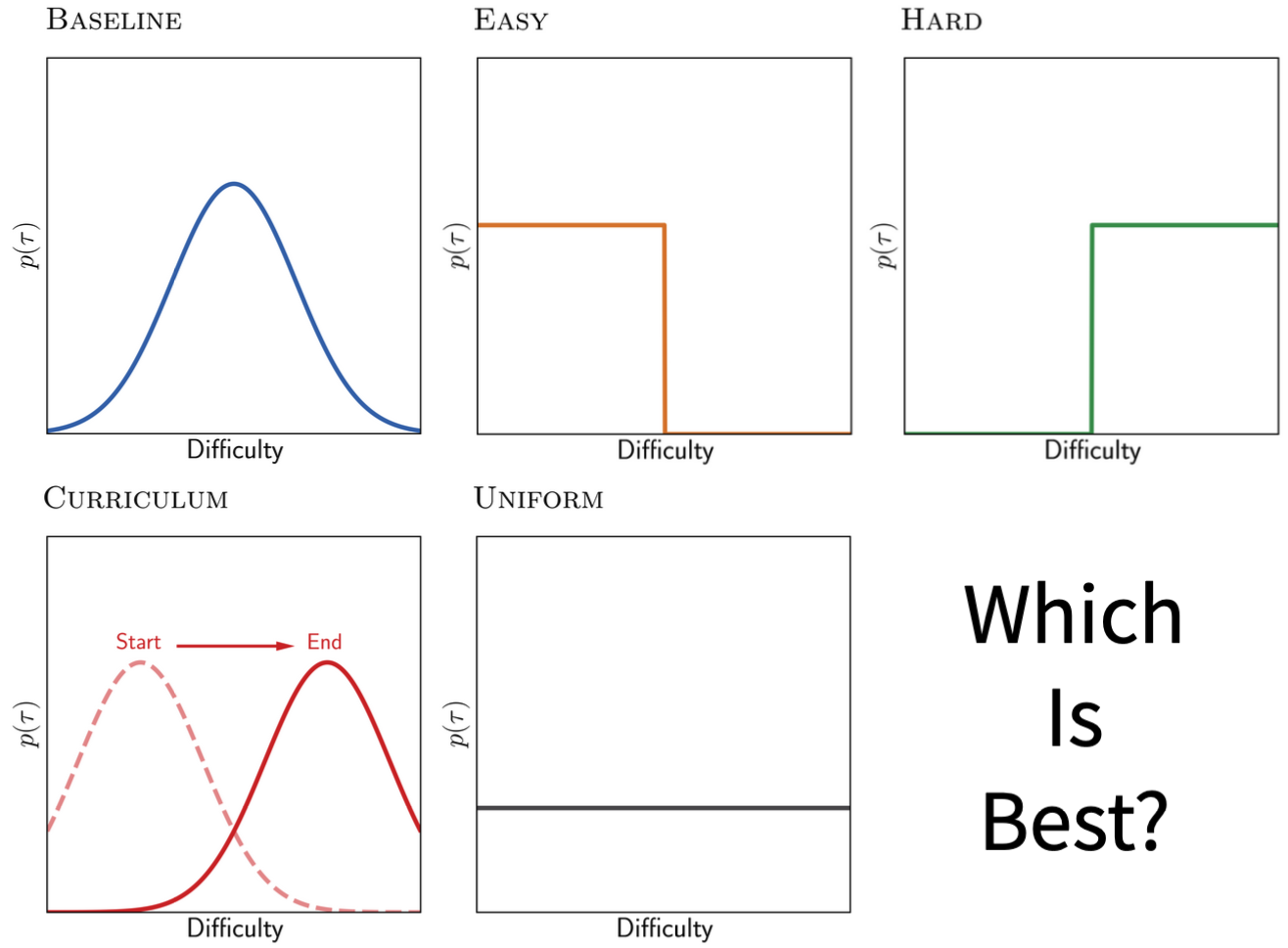
Episodic training is a core ingredient of few-shot learning to train models on tasks with limited labelled data. Despite its success, episodic training remains largely understudied, prompting us to ask the question: what is the best way to sample episodes? In this paper, we first propose a method to approximate episode sampling distributions based on their difficulty. Building on this method, we perform an extensive analysis and find that sampling uniformly over episode difficulty outperforms other sampling schemes, including curriculum and easy-/hard-mining. As the proposed sampling method is algorithm agnostic, we can leverage these insights to improve few-shot learning accuracies across many episodic training algorithms. We demonstrate the efficacy of our method across popular few-shot learning datasets, algorithms, network architectures, and protocols.

Code
Available at: github.com/amazon-research/uniform-episodic-sampling
Reference
Please cite this work as
S. M. R. Arnold, G. S. Dhillon, A. Ravichandran, S. Soatto, Uniform Sampling over Episode Difficulty. NeurIPS 2021.
or with the following BibTex entry.
@inproceedings{arnold2021uniform,
author = {Arnold, S\'{e}bastien M. R. and Dhillon, Guneet S. and Ravichandran, Avinash and Soatto, Stefano},
title = {Uniform Sampling over Episode Difficulty},
booktitle = {Advances in Neural Information Processing Systems},
volume = {34},
year = {2021}
}
Contact
Séb Arnold - seb.arnold@usc.edu
How to sample episodes to improve few-shot classification accuracy.
VenuePeople
Resources