Policy-Induced Self-Supervision Improves Representation Finetuning in Visual RL
Abstract
We study how to transfer representations pretrained on source tasks to target tasks in visual percept based RL. We analyze two popular approaches: freezing or finetuning the pretrained representations. Empirical studies on a set of popular tasks reveal several properties of pretrained representations. First, finetuning is required even when pretrained representations perfectly capture the information required to solve the target task. Second, finetuned representations improve learnability and are more robust to noise. Third, pretrained bottom layers are task-agnostic and readily transferable to new tasks, while top layers encode task-specific information and require adaptation. Building on these insights, we propose a self-supervised objective that clusters representations according to the policy they induce, as opposed to traditional representation similarity measures which are policy-agnostic (e.g. Euclidean norm, cosine similarity). Together with freezing the bottom layers, this objective results in significantly better representation than frozen, finetuned, and self-supervised alternatives on a wide range of benchmarks.
Summary
The paper is structured as follows:
- Analysis: where we show that good RL representations are robust to noise and tightly cluster states that yield similar optimal actions.
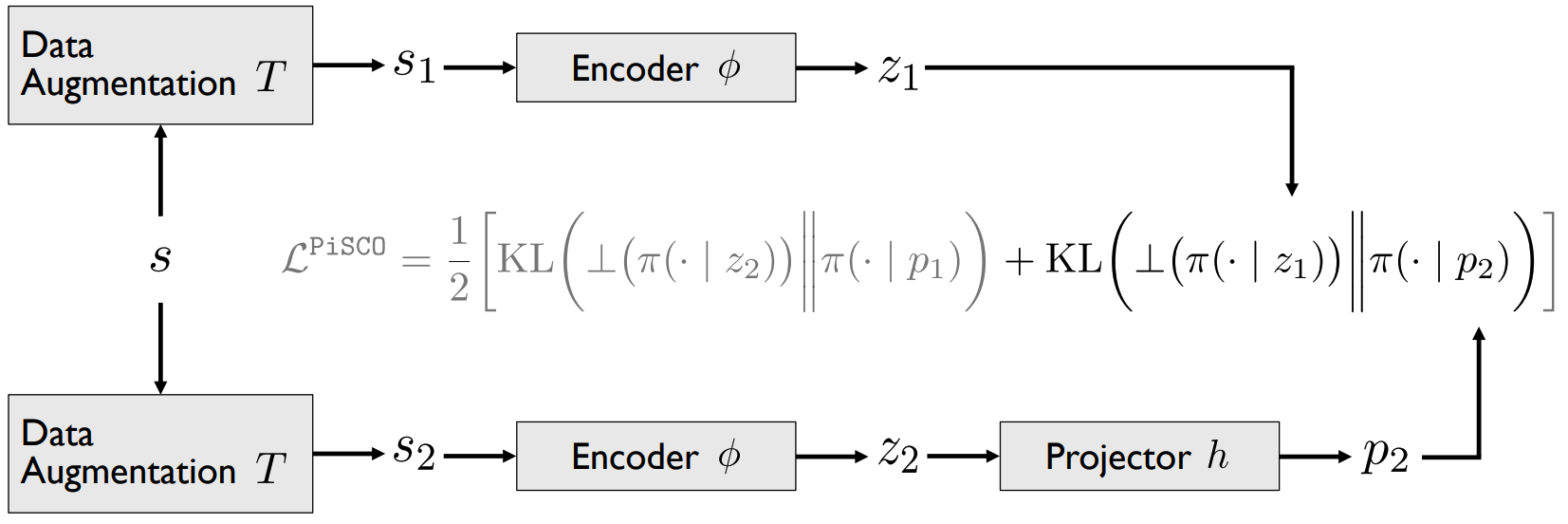
- Method: where we introduce PiSCO, a simple change on top of vision SSL objectives to tailor them to RL finetuning. PiSCO builds on our analysis by ensuring that all perturbations of a state yield similar policies — not just similar representations.
- Benchmarks: where we benchmark PiSCO against RL and RL+SSL methods on MSR Jump, DeepMind Control, and Habitat.
Our preprints also reiterates the importance of freezing task-agnostic representations, which is especially crucial to effectively finetune large feature extractors with RL.
Pseudocode
Example pseudocode of extending PPO with our PiSCO self-supervised objective. Similar pseudocode for DrQv2 is available in the Appendix of the paper, or at this address.
{kind=link}

Code
The following computes the PiSCO objective for a discrete policy. It uses PyTorch, cherry, and learn2learn.
# Compute PiSCO losses
z1 = policy.features(data_augmentation(states))
z2 = policy.features(data_augmentation(states))
p1 = projector(z1)
p2 = projector(z2)
pi_z1 = cherry.distributions.Categorical(logits=policy.actor(z1))
pi_p1 = cherry.distributions.Categorical(logits=policy.actor(p1))
pi_z2 = cherry.distributions.Categorical(logits=policy.actor(z2))
pi_p2 = cherry.distributions.Categorical(logits=policy.actor(p2))
kl1 = torch.distributions.kl_divergence(
p=l2l.detach_distribution(pi_z1),
q=pi_p2,
).mean()
kl2 = torch.distributions.kl_divergence(
p=l2l.detach_distribution(pi_z2),
q=pi_p1,
).mean()
pisco_loss = (kl1 + kl2) / 2.0Reference
Please cite this work as
S. M. R. Arnold, F. Sha, Policy-Induced Self-Supervision Improves Representation Finetuning in Visual RL. ArXiv 2023.
or with the following BibTex entry.
@ARTICLE{Arnold2023policy,
title = "Policy-induced self-supervision improves representation
finetuning in visual {RL}",
author = "Arnold, Sébastien M R and Sha, Fei",
publisher = "arXiv",
month = feb,
year = 2023,
url = "http://dx.doi.org/10.48550/arXiv.2302.06009"
}Contact
Séb Arnold - seb.arnold@usc.edu
A study of what makes for good representations in visual RL.
VenuePeople
Resources